I recently decided to learn more about Rust, and wrote a high performance RaptorQ (RFC6330) library. RaptorQ is a fountain code, and the core of the algorithm is a lot of matrix math over GF(256) – which translates into lots of XORs and reads from lookup tables. After getting the initial implementation working, I set about optimizing it. Below is a journal of the steps I took to profile and optimize the implementation. By the end, I’d achieved a 24.7x speedup!
v0.1.0: 39Mbit/s
Once the algorithm was working, I needed benchmarks. The criterion crate worked great for this, and will automatically calculate confidence intervals for you.
Version 0.1.0 took 2ms to encode 10KB (39Mbit/s), which I felt pretty good about since OpenRQ states that they get ~50Mbit/s. However, they note that an implementation, by Qualcomm, that they tested was 10x faster. Also, I found that the CodornicesRq project says they get ~1.2Gbit/s, so I knew mine could be faster.
Now that I had benchmarks in place, it was time to get a profiler working. “perf” took a bit of wrangling, and I recommend this blog post if you’re not familiar with perf and flamegraph.
Some tips:
- Use
RUSTFLAGS='-Cforce-frame-pointers'when compiling any code you want to run under perf, otherwise the backtraces are unlikely to be accurate. - Use
perf record --call-graph dwarfto further improve backtraces. - Set the following to preserve symbols in your release builds, so that they’re available to perf. Otherwise, you’ll just have function addresses rather than the names of the functions.
[profile.release]
debug = true
- If you have functions that you’re pretty sure don’t need to be inlined for performance reasons, you can use
#[inline(never)]to ensure that they show up in the backtraces. This can be useful to narrow down which function to optimize, as rustc inlines aggressively by default.
Below is an example of flamegraph, in which you can see that the GF(256) add and multiply functions are taking up almost all the time. (they’re the two big flat areas on top)
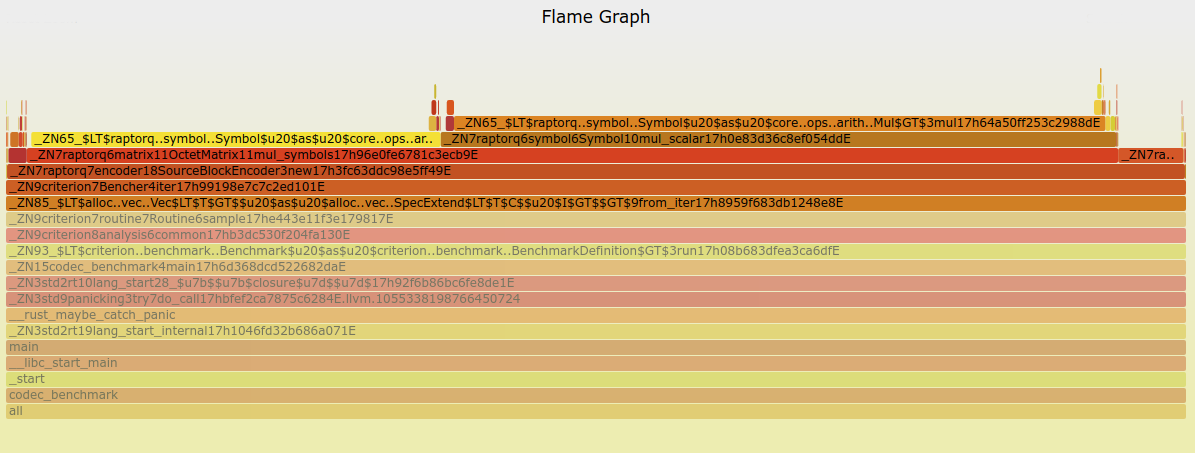
Armed with perf & flamegraph, v0.2.0 got a 3x performance improvement with some fairly straightforward optimizations. Mainly fusing the add and multiply function mentioned above into a fused-multiply-add operation to reduce memory allocations.
v0.2.0: 104Mbit/s
In the initial implementation, I had used a naive Gaussian elimination approach to matrix inversion. Now that I’d resolved the most obvious performance issues, I decided it was time to implement the optimized decoding algorithm described in RFC6330 section 5.4.
Unfortunately, this didn’t make things much faster for 10KB messages, but it did make the codec to scale linearly to larger blocks.
v0.3.0: 110Mbit/s
57% of the time was still spent in the fused-multiply-add function, so I had to find a way to make it faster. I created micro-benchmarks of the add and multiply operations, and started looking for ways to speed them up. I got a couple small wins by avoiding multiplications by 0 or 1, and then set about learning some more advanced Rust features: SIMD intrinsics, pointer casting and mut static.
I used precomputed multiplication tables to reduce the lookups required for a GF(256) multiply. This required the use of mut static and an initialization function to compute the multiplication table, since I wasn’t on Rust 1.31 yet (where const fn would have allowed me to do this. More on that later). I also tried lazy_static, but the overhead of the locking it does was much too high, since these tables are accessed on every multiply.
After that it was time for unsafe and some good old pointer casting and SIMD intrinsics. The SIMD support in Rust is quite nice to work with, and having done most of my professional coding in Python and Java, it’s really great to be able to use intrinsics so easily. as_mut_ptr() quickly became my friend, along with unsafe blocks, and pretty soon the GF(256) operations were ~10x faster.
Original code for += operation (addition is XOR under GF(256)):
fn add_assign(octets: &mut [u8], other: &[u8]) {
for i in 0..octets.len() {
unsafe {
*octets.get_unchecked_mut(i) ^= other.get_unchecked(i);
}
}
}
SIMD’ified version:
#[target_feature(enable = "avx2")]
unsafe fn add_assign_avx2(octets: &mut [u8], other: &[u8]) {
let octets_avx_ptr = octets.as_mut_ptr() as *mut __m256i;
let other_avx_ptr = other.as_ptr() as *const __m256i;
for i in 0..(octets.len() / 32) {
let octets_vec = _mm256_loadu_si256(octets_avx_ptr.add(i));
let other_vec = _mm256_loadu_si256(other_avx_ptr.add(i));
let result = _mm256_xor_si256(octets_vec, other_vec);
_mm256_storeu_si256(octets_avx_ptr.add(i), result);
}
let remainder = octets.len() % 32;
for i in (octets.len() - remainder)..octets.len() {
*octets.get_unchecked_mut(i) ^= other.get_unchecked(i);
}
}
v0.4.0: 223Mbit/s
Next, I applied SIMD to several other parts of the codec, and used cfg(debug_assertions) to disable some verification checks in release builds. Replacing the usage of HashMap with an ArrayMap (a map implementation backed by a Vec) also brought a nice performance gain.
v0.5.0: 511Mbit/s
I made some algorithmic changes to incrementally recompute stats, and then did a bunch more work cutting down on memory allocation/deallocation. I was somewhat surprised to get a 50% speedup just by systematically removing calls to clone(), replacing HashSet with a bitmap and a few other changes. One thing about Rust that I really came to appreciate is the clear distinction between moving, copying, and referencing memory. In my very first foray into Rust, I’d been quite frustrated with the borrow checker, but this time I realized that it makes performance easier to reason about, in addition to memory ownership.
v0.6.0: 797Mbit/s
The last optimization I made was replacing the petgraph library with a custom implementation that was tuned for just what I needed: RaptorQ only requires finding a single edge belonging to the largest connected component, not all the connected components.
v0.8.0: 965Mbit/s
At this point, I feel like there’s not a whole lot left to optimize, so I implemented a couple things to improve ease of use and polish up the library.
I’d been using compile time cpu detection, but this requires that you build with RUSTFLAGS='-C target-feature=+avx2' to take advantage of the SIMD speedups, and the resulting binary can’t run on systems that don’t support AVX2 (turns out my old MacBook Air falls in that category). Using dynamic CPU feature detection had the same performance, and makes the binary fully portable, as there’s a fallback code path when running on machines without AVX2.
Lastly, I upgraded to Rust 1.31 and replaced all the ugly mut static code with the new const fn feature. mut static had given a nice performance boost by storing a precomputed multiplication table, but it meant that an initialization function had to be called before the library could be used. Switching to const fn resolved this and even improved performance by moving the precomputation to compile time. It was a little more painful than I had expected because const fn doesn’t yet support loops or if statements, so I had to manually unroll loops to several hundred lines of code, but it was still worth it.
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email